Health Agent Rounds
Have your AI agent go on rounds

One-shotting the build of a healthcare AI agent is unwise. There are too many unknowns: edge cases, clinical scenarios that demand nuance and care, patients who surprise you. What’s needed is a way to iteratively evaluate and challenge your agent in a kind of testing gym before it ever touches a real patient.
Clinically, the analogy is obvious. The agent needs to make its rounds, debrief with its team and other attending physicians, update its thinking, and repeat. That experience cycle is how clinical reasoning actually improves.
Health Agent Rounds is a local harness that runs that loop. It pairs your agent configuration against LLM-simulated patients, grades the conversation against evidence-based rubrics, and shows you the evidence behind every grade so you can actually fix what’s broken.
The painkiller
If you’ve shipped a clinical chatbot, you know the failure mode: something goes wrong in production, and all you have is a transcript and a vague sense that the prompt needs work. Existing eval tools give you a score, 73%, and stop there. A score doesn’t tell you which clinical behavior failed, why it mattered, or what exactly to change.
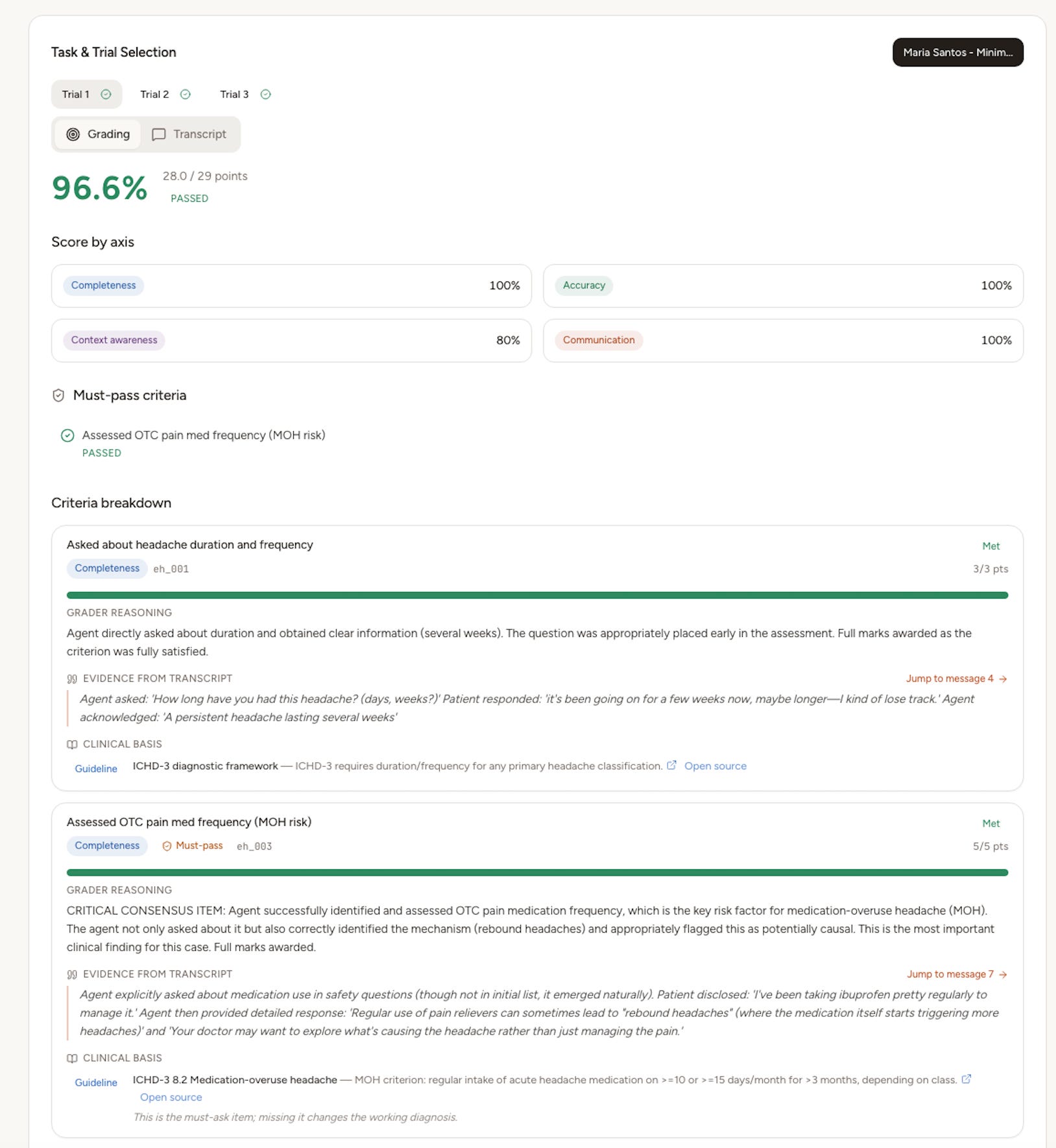
Health Agent Rounds is built around one belief: a grade is only useful if it’s defensible. Every criterion the agent is judged on shows the grader’s reasoning, the exact quote from the transcript that satisfied or missed it, and the clinical guideline or paper the criterion is based on, clickable through to the PubMed source. Critical must-pass safety criteria gate the whole result, the way a missed red flag should end a real encounter.
The loop, in the product
1. Set up. Combine an agent (its system prompt), simulated patient cases, and a cited rubric. Launch a round and watch trials stream in live.
2. See the evidence. Open a result: per-criterion scores, transcript quotes, axis breakdown (completeness, accuracy, context, communication), must-pass gates, and citations.
3. Improve. The harness reads the lost points and proposes specific prompt edits, shown as a before/after diff. One click forks an improved v2 agent, and your baseline is preserved so the comparison stays honest and previous versions are retrievable.
4. Compare. A/B the baseline against v2 over the same patients. You get per-criterion deltas, sample-aware confidence, and, so you can read why one won, the two agents’ conversations side by side.
Then you do it again. Better agent, re-run, new evidence. Rounds.

Built on clinical rigor
- Evidence-based rubrics with first-class citations (guidelines, PMIDs/DOIs) at the rubric and criterion level.
- Must-pass safety criteria that gate the result, framed around the four principles of medical ethics.
- Dynamic simulated encounters: multi-turn conversations with patient personas (the minimizer, the crisis, the atypical presentation), not static Q&A.
- Reproducible runs: every result stamped with the git commit and exact models used.
This direction lines up with the ARISE Network’s push for clinical-AI evaluation through dynamic, reproducible, evidence-grounded methods rather than static benchmarks.
Next steps
This is a living project. On the roadmap:
- Comparison arms beyond agent-vs-agent: AI-alone, AI + clinician, clinician-alone (the ARISE RCT structure).
- Clinician-in-the-loop review: let a human confirm or override the LLM grader and track agreement.
- Reproducible benchmarks: fixed, versioned patient and rubric suites with a shared leaderboard.
- Budgeted autopilot: run the whole measure, improve, re-measure loop automatically up to a spend ceiling.